Method
|
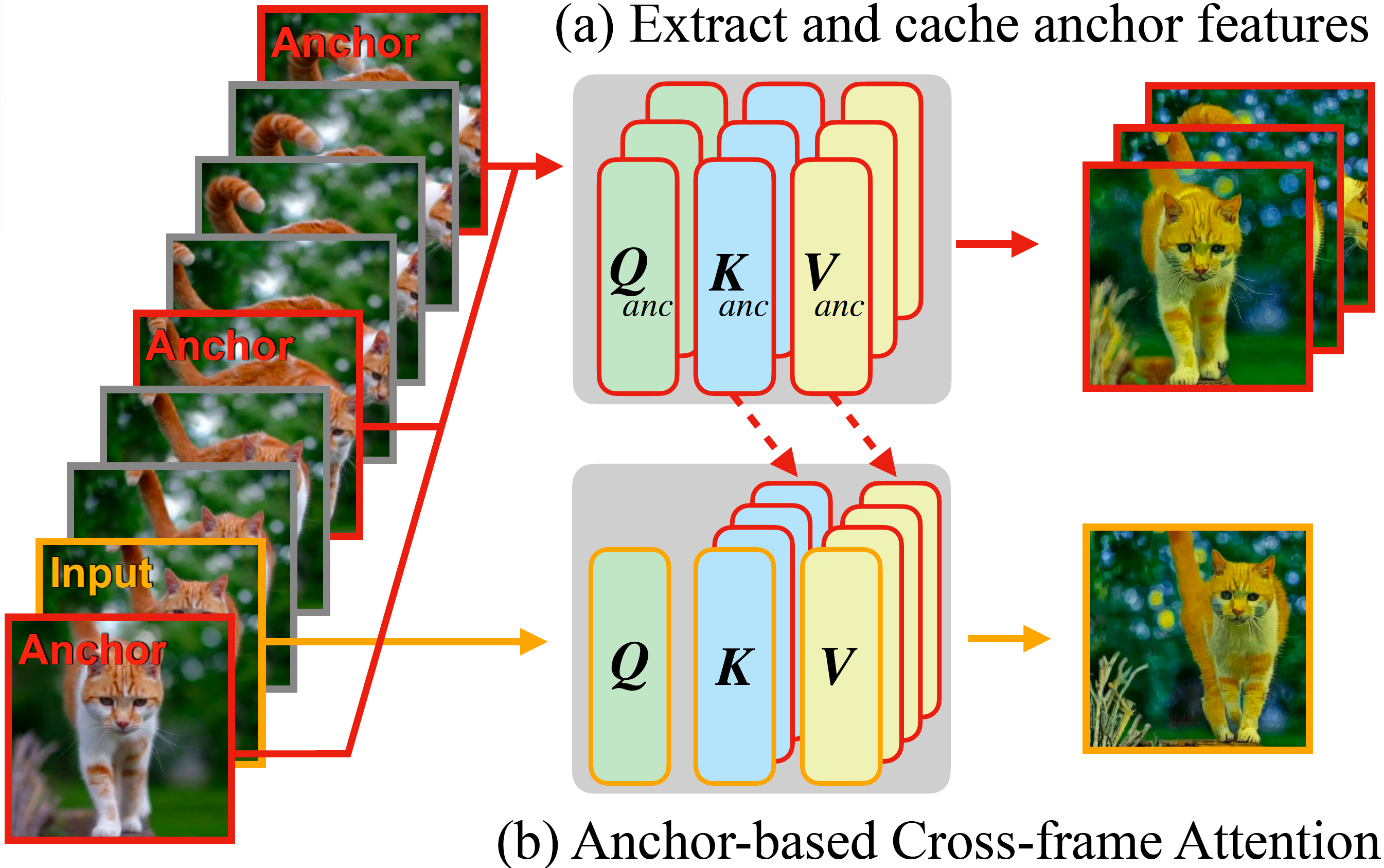
Fairy re-examines the tracking-and-propagation paradigm under the context of diffusion model features. In particular, we bridge cross-frame attention with correspondence estimation, showing that it temporally tracks and propagates intermediate features inside a diffusion model. The cross-frame attention map can be interpreted as a similarity metric assessing the correspondence between tokens throughout various frames, where features from one semantic region will assign higher attention to similar semantic regions in other frames, as shown in the following figure (Fig. 3). Consequently, the current feature representations are refined and propagated through a weighted sum of similar regions across frames via attention, effectively minimizing feature disparity between frames, which translates to improved temporal consistency. |
The analysis gives rise to our anchor-based model, the central component of Fairy. To ensure temporal consistency, we sample K anchor frames from which we extract diffusion features, and the extracted features define a set global features to be propagated to successive frames. When generating each new frame, we replace the self-attention layer with cross-frame attention with respect to the cached features of anchor frames. With cross-frame attention, the tokens in each frame take the features in anchor frames that exhibit analogous semantic content, thereby enhancing consistency.